- Distribuciones más utilizadas de Linux
- Instalación de Ubuntu Server
- Instrucciones para instalar Rocky
- Gestión del árbol de directorios
- Diferencias entre LESS CAT HEAD y TAIL para lectura de archivos
- Interacción con archivos y permisos
- Conociendo las terminales en linux
- Manejo y monitoreo de procesos y recursos del sistema
- Monitoreo de recursos del sistema
- Análisis de los parámetros de red
- Administración de paquetes acorde a la distribución
- Manejo de paquetes en sistemas basados en Debian
- Administración de software con YUM y RPM para CentOS
- Nagios: Desempaquetado, descompresión, compilación e instalación de paquetes
- Los usuarios, una tarea vital en el proceso de administración del sistema operativo
- Creando y manejando cuentas de usuario en el sistema operativo
- Entendiendo la membresía de los grupos
- Usando PAM para el control de acceso de usuarios
- Autenticación de clientes y servidores sobre SSH
- Configurando DNS con bind
- Arranque, detención y recarga de servicios
- NGINX y Apache en Ubuntu server
- Instalación y configuración de NGINX
- ¿Qué es NGINX Amplify?
- Monitoreo de MySQL con Nagios
- Configuración de Nagios
- Los logs, nuestros mejores amigos
- Las bases de bash
- Automatizando tareas desde la terminal
- Crontab
- Entendiendo la gestión de vulnerabilidades
- ¿Qué es una superficie de ataque? Principio del menor privilegio
- Configuración de Node.js en un ambiente productivo
- Vamos a usar dos distribuciones de Linux: Ubuntu Server en su versión 18.04 y Rocky-8.5 RedHat.

- Importante: Se deben instalar las versiones LTS (Long Term Support), ya que ofrecen soporte de al menos 5 años
- Descargar Virtual Box: VirtualBox
- Descargar Ubuntu Server: Ubuntu
- Crear una nueva máquina virtual
- En la configuración de nuestra máquina, en la sección Red cambiar de NAT a Adaptador puente. En avanzadas, colocar en el Modo promiscuo “Permitir todo”
- En la sección Storage seleccionamos el cd que dice “Vacío”, y en el apartado de atributos a la derecha seleccionamos el icono del cd para buscar nuestra imagen ISO de Ubuntu ya descargada anteriormente. Aceptamos los cambios.
- Iniciamos la máquina virtual
- Si estamos trabajando en un servidor físico, deberíamos seleccionar “Comprobar memoria” Instalamos el sistema operativo
Notes: Si estas en windows 11/10 y Hyper-V no te permite correr VirtualBox 6.1 independiente de la version LTS de Ubuntu, entonces te recomiendo usar VirtualBox 5.2 y que desactives Hyper-V a través de bcdedit /set hypervisorlaunchtype off, si usas WSL2 probablemente
te aparezca el siguiente mensaje Please enable the Virtual Machine Platform Windows feature and ensure virtualization is enabled in the BIOS. pero no te preocupes puedes volver al estado inicial con bcdedit /set hypervisorlaunchtype auto no importa cuantas veces tengas que hacer este proceso solo recuerda REINICIAR tu pc para que los cambios se guarden correctamente. Revise muchos foros de VirtualBox y lo mejor que puedes hacer para realmente descubrir el problema es a través de los logs a los cuales puedes acceder, apagando la VM, click derecho sobre VM > Mostrar Trazas o Show Log. 👍
- Descargar VirtualBox
- Descargar Rocky-8.5
- Crear una nueva máquina virtual
- En la configuración de nuestra máquina, en la sección Red cambiar de NAT a Adaptador puente. En avanzadas, colocar en el Modo promiscuo “Permitir todo”
- En la sección Storage seleccionamos el cd que dice “Vacío”, y en el apartado de atributos a la derecha seleccionamos el icono del cd para buscar nuestra imagen ISO de CentOS ya descargada anteriormente. Aceptamos los cambios
- Iniciamos la máquina virtual
- Instalamos el sistema operativo
- En la configuración, en el apartado de NETWORK & HOST NAME, activar la interfaz con el botón “on”. Cambiamos el host name a “platzi-server” y damos click en aplicar
- En el apartado de INSTALLATION DESTINATION seleccionamos el disco de Virtual Box
- Configuramos la hora y damos click en done
- Hacemos click en ROOT PASSWORD y creamos una contraseña para el usuario root
- Creamos un usuario nuevo dando click en USER CREATION y finalizamos la instalación.
pwd: nos muestra nuestra ubicación actual en el árbol de directorios (Print Working Directory).ls: nos muestra el contenido de las carpetas de nuestro sistema operativo. Podemos especificar alguna ruta o, por defecto, listar el contenido de la carpeta donde estamos trabajando.cd: cambiar nuestra ubicación en el árbol de directorios (Change Directory). Usamos dos puntos (..) para referirnos al directorio padre y solo uno (.) para referirnos a nuestro directorio actual.touch: nos ayuda a crear archivos desde la terminal.mkdir: nos ayuda a crear carpetas desde la terminal.cp: nos permite duplicar archivos y carpetas.mv: cambiar el nombre de nuestros archivos y carpetas.
cat: Muestra un archivo sin paginar.less: Muestra un archivo paginado. Pulsando “/” y escribiendo una palabra, puedo buscar las coincidencias de la misma en el archivo. Con la tecla “n” me muevo entre coincidencias hacia adelante, y conshift + nme muevo entre coincidencias hacia atras. Con espacio cambio de página.tail: Muestra las últimas 10 líneas de un archivo específico. Con la opción-npuedo modificar la cantidad de líneas que veo. Con la opción -f puedo poner los cambios en escucha.head: Muestra las primeras 10 lineas de un archivo específico. Con la opción-npuedo modificar la cantidad de líneas que veo.man: Muestra ayuda sobre comandos.
-
Con el comando
ls -lpodemos observar la lista de archivos de nuestro directorio actual con información un poco más detallada. El primer campo nos indica los diferentes permisos para cada archivo o directorio. Por ejemplo:-rwxrw-r--. -
El primer carácter nos indica si tenemos un archivo (-), enlace simbólico (l) o directorio (d).
-
Los siguientes caracteres se dividen en grupos de 3: lectura r, escritura w y ejecución x. El primer grupo son los permisos del usuario que creó ese archivo, el segundo para el grupo al que pertenece este usuario y el tercero para cualquier otro usuario de tu sistema operativo.
-
Los grupos nos ayudan a darle los mismos permisos a diferentes usuarios sin necesidad de asignarlos a cada uno individualmente. Todos los usuarios que pertenezcan al grupo tendrán los mismos permisos.
-
Si en vez de estas letras encuentras un guion significa que ese usuario o grupo de usuarios no tiene permiso para esa acción en particular.
Por ejemplo: -rwxrw-r-- nos indica que trabajamos con un archivo. Todos los usuarios del sistema tienen permisos de lectura. El usuario creador y su grupo tienen permiso de escritura. Y solo el usuario creador puede ejecutar el archivo.
También podemos encontrar estos permisos como 3 números del 1 al 7. Estos números son la suma de los 3 caracteres de permisos para cada usuario o grupo.
- = 0x = 1w = 2r = 4Por lo tanto, los permisos de nuestro archivo de ejemplo serían:7 (1+2+4) 6 (0+2+4) 4 (0+0+4).
Para cambiar los permisos de un archivo o directorio podemos usar el comando chmod + a quién queremos añadir o quitar los permisos:
- El usuario propietario:
u. - El grupo,
g. - El resto de usuarios,
o. - Para todos,
a.
Por ejemplo, para añadir permisos de ejecución a nuestro usuario propietario usamos:
chmod u+x nombre-del-archivo
También podemos cambiar al usuario propietario del archivo con el comando chown.
-
sudo chown nuevo-usuario:grupo-usuarios nombre-del-archivo -
Cambiar usuario
su username
chvt: Cambia de terminaltty: Muestra la terminal actualwho: Muestra los usuarios conectados a nuestro sistemaw: Hace lo mismo que el comando who pero muestra más informaciónps: Muestra los procesos corriendo. Con los modificadores -ft y tty podemos filtrar para ver las conexiones de los usuarioskill: Mata un proceso. Con el modificador -9 fuerzo el cierre del mismo
Comandos |
ps: Muestra los procesos corriendo. Modificadores:aux: Muestra todos los procesosjobs: Al igual que el comando anterior, muestra los procesos. A diferencia de ps, es un comando interno de la terminalfg: Abre un proceso que estaba pausadonohup: Genera un archivo llamado “nohup.out” que muestra toda la información que produjo un procesogrep: Nos ayuda a filtrar el resultado de un comando o el contenido de un archivo dependiendo de las palabras (o incluso expresión regular) que le indiquemo.
Lo que significa cada parametro al ejecutar el comando ps aux
USER: usuario con el que se ejecuta el procesoPID: ID del proceso%CPU: porcentaje de tiempo que el proceso estuvo en ejecución desde que se inició%MEM: porcentaje de memoria física utilizadaVSZ: memoria virtual del proceso medida en KiBRSS: “resident set size”, es la cantidad de memoria física no swappeada que la tarea a utilizado (en KiB)TT: terminal que controla el proceso (tty)STAT: código de estado del proceso (información detallada más adelante)STARTED: fecha de inicio del procesoTIME: tiempo de CPU acumuladoCOMMAND: comando con todos sus argumentos
-
top: Muestra la siguiente información del sistema: -
load average (carga promedio): Provee una representación en números del 1 al número de procesadores que tenga nuestro servidor del uso de los mismos. Uso de la memoria, Cantidad de usuarios, Uso del CPU, Procesos, Etc.
-
free: Me muestra información sobre la memoria de mi sistema. Con el modificador -h la información es más legible para un humano -
du: Muestra información sobre el disco duro. Con el modificador -hsc y un directorio especificado muestra el tamaño de ese directorio -
htop: Funciona como top pero funciona de forma más intuitiva
Comandos útiles
cat /proc/cpuinfo | grep "processor": Muestra información sobre el CPUsudo ps auxf | sort -nr -k 3 | head -5: Muestra los 5 procesos que más uso hacen del CPUsudo ps auxf | sort -nr -k 4 | head -5: Muestra los 5 procesos que más uso hacen de la memoria RAM
Comandos
ifconfig: Interface Configuration, muestra las tarjetas de red que tenemos y su direccionamiento específicoip a: IP Address Show, muestra las direcciones IPhostname: Como se identifica este equipo en la redroute -n: Muestra cual es el dispositivo que me permite conectarme a internetnslookup: Muestra la dirección IP de un dominio determinadocurl: Realiza consultas a un servidorwget: Permite descargar contenido de un servidor
Comandos útiles
ip -4 a: Muestra las direcciones IPv4ip -6 a: Muestra las direcciones IPv6
Ubuntu server
- Repositorios:
apt - Extensión de paquetes:
.deb
Comandos:
dpkg -l: Lista todos los deb instalados en la máquinadpkg -i paquete.deb: Instala un paquetedpkg -r paquete.deb: Desinstala un paquetedpkg-reconfigure paquete: Permite configurar nuevamente un paqueteapt install paquete: Instala un paquete desde un repositorioapt search paquete: Busca un paquete en un repositorio
Rocky
Repositorios: yum
Extensión de paquetes: .rpm
Comandos:
rpm -qa: Lista todos los rpm instalados en la máquinarpm -i paquete.rpm: Instala un paqueterpm -e paquete.rpm: Desinstala un paqueteyum install paquete: Instala un paquete desde un repositorioyum search paquete: Busca un paquete en un repositorio
-
sudo apt upgradeNo se trata solo de hacer el upgrade debemos verificar que que es lo que va a actlizar y que eso no valla a afectar nuestro ambiente de programacion. -
sudo apt dist-upgradeA diferencia del comando anterior este upgrade se realiza a nivel de Kernel, razón por lo cual se debe ser mas precavido puesto que podriamos romper algunos programas. -
LivePatch nos permite realizar actualizaciones en e sistema sin necesidad de realizar reinicios.
-
sudo apt search mysqlMe permite buscar todos lo paquetes conformados por la keyword "mysql" -
sudo apt search "mysql-server$"Es mas especifico que es importante colocar el signo$ -
sudo apt-cache search "mysql-server$"Es exactamente lo mismo que el comando anterior -
dpkg -lLista los paquetes de mi OS -
sudo dpkg-reconfigure tzdataToma el paquetetzdatapara configurar la zona horaria, y asi podemos espesificar nuevamente que zona horario queremos usar. -
sudo snap search aws-cliSnap es tambien un gestor de paquetes de debian, en este caso podemos buscar la consola de amazon, Snap fue desarrollado Canonical, los mismos creadores de Ubuntu ccon el tiempo se ha ido migrando de apt a snap paulatinamente. -
sudo snap refresh --listAsi podemos ver todos los paquetes instalados en nuestro gestor snap -
sudo snap info aws-cliAsi podemos consultar un paquete de snap en especifico -
sudo snap install canonical-livepatch
-rpm -qa Lista todos los paquetes de rpm a -> all
rpm -qi bashBuscaiinformacion del paquete bash.rpm -qc bashIndica las rutas de los archivos involucrados en la configuracioncde Bash.rpm -e curlBorraeo intenta borrar un paquete del repositorio si el sistema lo permite.
No todo el software que necesitamos se encuentra en los repositorios. Debido a esto, algunas veces debemos descargar el software, realizar un proceso de descompresión y desempaquetado para finalmente instalar la herramienta.
Instalación de algunas herramientas para manejar una base de datos MySQL
sudo apt install build-essential libgd-dev openssl libssl-dev unzip apache2 php gcc libdbi-perl libdbd-mysql-perl
- Build-essentials: The build-essentials packages are meta-packages that are necessary for compiling software.
- libgd-dev: It allows your code to quickly draw images complete with lines, arcs, text, multiple colours, cut and paste from other images, flood fills, and write out the result as a PNG file.
- Unzip: Paradescomprimir archivos zip
- Apache2: The goal of this project is to provide a secure, efficient and extensible server that provides HTTP services in sync with the current HTTP standards. ASi podremos soportar nagios😀
- php: PHP is mainly focused on server-side scripting
- gcc: GCC development is a part of the GNU Project, aiming to improve the compiler used in the GNU system including the GNU/Linux variant.
- libdbi-perl: Es un entorno de desarrollo en Perl que proporciona una interfaz común para acceder a varios sistemas de bases de datos de una manera uniforme.
- libdbd-mysql-perl: DBD::mysql is the Perl5 Database Interface driver for the MariaDB/MySQL database. In other words: DBD::mysql is an interface between the Perl programming language and the MySQL programming API that comes with the MariaDB/MySQL relational database management system.
Instalación de Nagios: Nagios monitors your entire IT infrastructure to ensure systems, applications, services, and business processes are functioning properly.
wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.4.tar.gz -O nagioscore.tar.gz
Descomprimir y desempaquetar archivos con tar:
tar xvzf nagioscore.tar.gz
Este comando creará una carpeta nagios-4.4.4. El nombre de la carpeta puede variar dependiendo de la versión que descargaste. Entrando a esta carpeta podemos ejecutar diferentes archivos y comandos para configurar el software y realizar la instalación.
sudo ./configure --with-https-conf=/etc/apache2/sites-enabled. Permite configurar el software que vamos a instalar../configurees un archivo dentro de la carpeta nagios-4.4.4. luego con el comando--with-https-conf=le indicamos que los queremos configurar con apache2 entregandole la ruta donde esta apache2.
sudo make allVerifica todos los archivos de configuracion anteriormente creados.sudo make install-groups-usersthensudo usermod -a -G nagios www-datafinallysudo make installBy definition, if you are doing make install that means you are making a local installsudo make install-initThis installs the init script in /lib/systemd/system.sudo make install-commandmodeThis installs and configures permissions on the directory for holding the external command file.sudo make install-configThis installs sample config files in /usr/local/nagios/etc. Remember, these are SAMPLE config files.sudo make install-webconfPermite habilitar el módulo Apache necesario para la interfaz web de Nagios -> Nagios/Apache conf file installed.- Por último, para administrar el servicio de nagios podemos usar los comandos
sudo systemctl (status, start, restart, reload, stop, enable, disable, list-dependencies) nagios
- Si queremos ver que hay en el localhost desde la terminal podemos ejecutar el comando
curl localhostocurl localhost | grep apachepara ver si esta relacionado con apache. - Nagios ps si solo no es muy funcional a menos que le instalemos plugins por esta razon es importante hacerlo:
-
El comando
idnos muestra el identificador único (uid) de cada usuario en nuestro sistema operativo. El ID 0 está reservado para el usuario root. En debian Ubuntu Server los Id's inician desde 1000 y en CentOS RedHat inician desde 500. -
Con el comando
whoamipodemos ver con qué usuario estamos trabajando en este momento. Podemos ver todos los usuarios del sistema leyendo el archivocat /etc/passwd. Aqui podemos ver todos los usuarios del sistema operativo que son necesarios para que el sistema operativo funcione. -
Las contraseñas de los usuarios están almacenadas en el archivo
cat etc/shadow, pero están cifradas. Y solo el usuarioroottiene permisos de lectura/escritura.
Para cambiar la contraseña de nuestros usuarios usamos el comando passwd.
Comandos para administrar cuentas de usuarios:
sudo useradd nombre-usuario: crea un usuario sin asignarle inmediatamente alguna contraseña ni consultar más información. Debemos terminar de configurar esta cuenta a mano posteriormente.sudo adduser nombre-usuario: crea un nuevo usuario con contraseña y algo más de información. También creará una nueva carpeta en la carpeta /home/.userdel nombre-usuario: eliminar cuentas de usuarios.usermod: modificar la información de alguna cuenta.exitpara salir de un usuario y volver al inicial
Nunca modifiques a mano el archivo /etc/passwd. Para administrar los usuarios debemos usar los comandos que estudiamos en clase.
-
Los grupos nos ayudan a darle los mismos permisos a diferentes usuarios al mismo tiempo, sin necesidad de asignar el mismo permiso a cada usuario individualmente. Todos los usuarios que pertenezcan al mismo grupo tendrán los mismos permisos.
-
Para cambiar de usuario sin necesidad de reiniciar el sistema podemos usar el comando
su - nombre-usuario. También podemos cambiar de usuario sin necesidad de saber su contraseña usando el comandosudo su - nombre-usuario. -
Para ver a qué grupos pertenecen nuestros usuarios usamos el comando
groups nombre-usuario. Para agregar usuarios a un nuevo grupo usamos el comandosudo gpasswd -a nombre-usuario nombre-grupo. Los eliminamos de la misma forma congpasswd -d. -
Para esto también podemos usar el comando
sudo usermod -aG nombre-grupo nombre-usuario. Recuerda que en este caso el orden en que escribimos el grupo y el ususario se invierte. -
Para listar los permisos de nuestros usuarios ejecutamos el comando
sudo -l.
-
PAM es un mecanismo para administrar a los usuarios de nuestro sistema operativo. Nos permite autenticar usuarios, controlar la cantidad de procesos que ejecutan cada uno, verificar la fortaleza de sus contraseñas, ver la hora a la que se conectan por SSH, entre otras.
-
Con el comando
pwscorepodemos probar qué tan fuertes son nuestras contraseñas Donde el puntaje va de 0 a 100. Recuerda que para usar este comando en sistemas basados en Ubuntu debemos instalar el paquetesudo apt install libpwquality-tools. Siempre que debemos validar nuestros passwords conpwscoreantes de asignarlas a los usuarios -
El comando
ulimitnos ayuda a listar los permisos de nuestros usuarios. Para limitar el número de procesos que nuestros usuarios pueden realizar ejecutamosulimit -u max-numero-procesos. Para verificar que realmente se limitoel numero de procesos entonces podemos crear un script script.sh
#!/bin/bash
#Imprime en pantalla 'Hola'
echo 'Hola'
#Llama el comando anterior varias veces como un loop
$0- La consola ejecuta script.sh hasta que se han cumplido la cantidad maxima de procesos.
- A continuacion algunos de los flags de
ulimit
ulimit -n ⟶ It will display number of open files limit
ulimit -c ⟶ It display the size of core file umilit -u ⟶ It will display the maximum user process limit for the logged in user. ulimit -f ⟶ It will display the maximum file size that the user can have. umilit -m ⟶ It will display the maximum memory size for logged in user. ulimit -v ⟶ It will display the maximum memory size limit
SSH es un protocolo que nos ayuda a conectarnos a nuestros servidores desde nuestras máquinas para administrarlos de forma remota. ❌NO es muy recomendado usar otros protocolos como Telnet, ya que son inseguros y están deprecados.
Con el comando ssh-keygen podemos generar llaves públicas y privadas en nuestros sistemas, de esta forma podremos conectarnos a servidores remotos o, si es el caso, permitir que otras personas se conecten a nuestra máquina. Para comprobar que la llave fue creada listamos ls .ssh alli debe aparacer tanto id_rsa.pub Llave Publica como id_rsa Lave Privada
-
Para conectarnos desde nuestra máquina a un servidor remoto debemos:
-
Ejecutar el comando
ssh-copy-id -i ubicación-llave-pública nombre-usuario@dirección-IP-servidor-remotoy escribir nuestracontraseñapara enviar nuestra llave pública al servidor. Asissh-copy-id -i ~/.ssh/id_rsa.pub danmuner@192.168.xx.xx -
Usar el comando
ssh danmuner@192.168.xx.xxpara conectarnos al servidor sin necesidad de escribir contraseñas. -
vim /etc/ssh/sshd_configAsi podemos modificar otras opciones de ssh
Las configuraciones de SSH se encuentran en el archivo /etc/ssh/sshd_config como
# To disable tunneled clear text passwords, change to no here!
PasswordAuthentication no
#PermitEmptyPasswords no
Ahora siempre que realizemos cambios sera necesario reiniciar
sshsudo systemctl stop sshpara deneter sshsudo systemctl start sshpara iniciar ssh.
- También podemos usar el comando
ssh -vvvv danmuner@192.168.xx.xxpara ver la información o los errores de nuestra conexión con el servidor.
Contexto histórico de los DNS En Junio de 1983 alrededor de 70 sitios estuvieron conectados a la red de ciencias de la computación, permitiendo de esta forma la unión de algunos establecimientos gubernamentales, científicos y universitarios para que pudieran compartir datos, por esta razón los archivos de host no eran suficientes para hacer la replicación entre sitios, por este motivo en noviembre de 1983 se publicó el RFC 882 que define el servicio de nombre de dominios. Paso siguiente en octubre de 1984 se crearon 7 TLDs (Dominios de nivel superior) o también conocidos como dominios de propósito general .arpa, .com, .org, .edu, .gov, .mil y la letra de los países respetando su código ISO [1]
Instalación de Bind
- Para realizar el proceso de instalación de
bindlo primero que realizaremos es verificar que bind se encuentre en los repositorios, para esto utilizaremos otro gestor de paquetes llamadoaptitude, para instalarlo simplemente diremos
sudo apt install aptitude.
- Con aptitude instalado buscaremos el paquete
bindutilizando para ellos una expresión regular.
aptitude search "?name(^bind)"
-
Instalamos bind. El proceso de instalación se realiza con
sudo apt install -y bind9, la opción-yes para confirmar que si queremos instalar el paquete en mención. -
Validamos la instalación con
netstaty verificaremos que el puerto 53 este escuchando asisudo netstat -ltnp. Sabemos que es el puerto 53 xxx.xxx.xxx.xxx:53 porque despues de los dos puntos aparece el numero del puerto. -
Para realizar consultas al DNS podemos utilizar varias herramientas, entre ellas
dig, que me permiten conocer más al respecto del nombre de dominio, para ello usaremos el dominioplatzi.comy lo buscaremos en la máquinalocal, es decir127.0.0.1.
dig www.platzi.com @127.0.0.1Nos interesa la parte de respuesta y la de tiempo de ejecución para validar que la respuesta se dio desde localhost.
-
Paso siguiente después de instalarlo es verificar todo lo que viene incluido dentro del paquete como lo son los archivos de configuración manuales entre otros, para esto podemos hacer uso de
dpkg -L bind9. -
El archivo de configuración principal será
/etc/bind/named.conf, también tenemos el archivo/etc/bind/rndc.keyen este se puede configurar la clave que se puede usar para obtener acceso al nombre de dominio. -
Podemos ver la versión de bind de dos formas
named -vo una versión extendida connamed -V -
Si deseas adquirir tu DNS, tienes varias opciones:
- Namecheap
- Hover
- Route 53
-
Como cliente tienes varias opciones para configurar tus DNS, lo que influirá directamente en tu velocidad, seguridad o reputación. Para eso te daré algunas opciones, el orden no significa nada:
- OpenDns
- Google DNS
- Neustar UltraDNS
- Cloudflare
- quad
- Public DNS
- Yandex DNS
- Existe una herramienta que nos permite seleccionar cuál será el DNS que debemos utilizar basados en nuestra ubicación y nuestras búsquedas, se llama
namebench. Para ello sólo basta instalarlo y ejecutarlo en la máquina cliente y con esto obtendremos sugerencias al respecto. namebanch
-
El comando
systemctlnos permite manejar los procesos de nuestro sistema operativoGestor de Arranque. Nuestros servicios pueden estar activos (es decir, encendidos) o inactivos (apagados). También podemos configurar si están habilitados o deshabilitados para correr automáticamente con el arranque del sistema. E.g.sudo systemctl status apache2dependiento el estado el servcio se va o no a iniciar junto con el sistema operativo.stopstartrestartenabledisablestatuslist-units -t service --allLista unidaes de todos los servicios
-
sudo systemctl status nombre-servicio: ver el estado de nuestros servicios. -
sudo systemctl (enable, disable) nombre-servicio: activar o desactivar el arranque automático de nuestros servicios. -
sudo systemctl (start, stop, restart) nombre-servicio: encender, apagar o reiniciar los servicios. -
sudo systemctl list-units -t service --all: ver todos los servicios del sistema. -
El comando
journalctlnos permite ver los logs de los procesos de nuestro sistema operativo. Recuerda que todos ellos están almacenados en la carpeta/var/log/. -
sudo journalctl -fu nombre-servicio: ver los logs de nuestros servicios y hacer un seguimiento. -
sudo journalctl --disk-usage: ver la cantidad de espacio que ocupan nuestros logs. -
sudo journalctl --list-boots: muestra la lista de booteos de la computadora. -
sudo journalctl -p (critic, info, warning, error): filtrar los logs por el tipo de mensaje. -
sudo journalctl -o json: ver los logs en formato JSON.
NGINX y Apache son softwares para montar servidores web, puedes realizar la instalación de ambos en el sistema operativo, teniendo como base que pueden estar corriendo al mismo tiempo, siempre y cuando no estén a la espera de conexiones por el mismo puerto.
- Para validar los puertos que tienen un proceso activo usamos:
sudo netstat -tulpn
- Podríamos tener una infraestructura donde NGINX puede servir como proxy y Apache como servidor web.

-
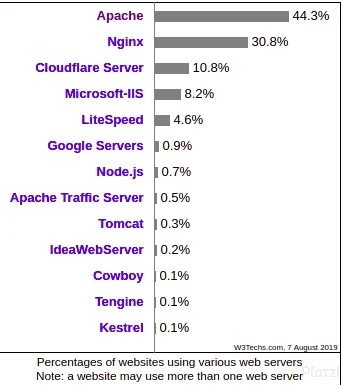
Si revisamos las estadísticas podemos ver que Apache aún es el líder del mercado en servidores web, seguido por NGINX, es por esta razón que veremos la instalación y configuración de ambos.
-
Existen en internet artículos interesantes de comparación entre ambos y el caso de uso de cada uno de ellos.
- Installacion
Apache Ejecuta el siguiente comando
sudo apt install apache2
NGINX Ejecuta el siguiente comando
sudo apt install nginx nginx-extras
-
Para verificar si los servicios está corriendon se debe ejecutar los siguientes comandos:
systemctl status apache2systemctl status nginx
-
Si se siguió el orden de instalación, NGINX no debe estar ejecutándose, pues por defecto intentará levantarse en el puerto 80, el cual ya se encuentra ocupado por Apache, para ello cambiaremos el puerto de Apache al puerto alterno http 8080.
sudo nano /etc/apache2/ports.conf- A continuación tenemos que cambiar el puerto al 8080, para esto se debe cambiar la instrucción
Listen _8080_dentro del documentoports.conf. - Después abrimos nuestro archivo de configuración de Apache
sudo nano /etc/apache2/sites-available/000-default.confy cambiamos el virtualhost a8080 <VirtualHost *:8080>
-
Después realizamos el proceso de detener apache2 y volverlo a encender, con los siguientes comandos.
sudo systemctl restart apache2systemctl status apache2systemctl status nginx
- Ambos sitios deberían estar activos y en ejecución.
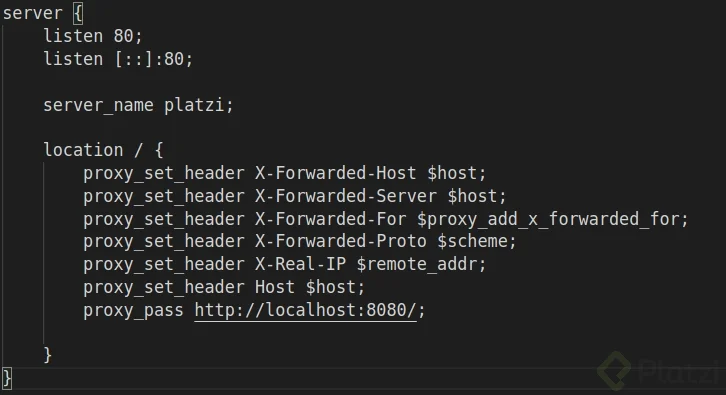
Paso siguiente, dirígete al archivo de configuración de NGINX donde te asegurarás que exista una directiva en el location llamada
proxy_passque contenga lo siguiente:proxy_pass http://127.0.0.1:8080
-
Si por alguna razón el servidor Apache no se encuentra en la misma máquina, debemos cambiar la dirección IP y el puerto respectivo.
- Apache tiene un comando para activar sitios que es
a2ensiteque recibe como parámetro el archivo de configuración definido en/etc/apache2/sites-available. NGINX no cuenta con este comando, motivo por el cual se tiene un enlace blando, es decir, cuando creemos un archivo de configuración en/etc/nginx/sites-availabledebemos ejecutarsudo ln -s /etc/nginx/sites-available/configuracion_nginx /etc/nginx/sites-enabled/
- Apache tiene un comando para activar sitios que es
- Apache también me permite deshabilitar sitios y agregar módulos
sudo a2dissite 000-default
sudo a2enmod rewrite headers env dir mime
- Si queremos activar
letsecrypten NGINX, debemos agregar una línea en el.htaccessen la ruta/var/www/html/nombre_host/.htaccess. La linea esSetEnvIf X-Forwarded-Proto https

- Conclusión Antes de realizar la elección de uno de los dos, deberías mirar el tipo de proyecto en el que estás trabajando y que se acople mejor a tus necesidades, es un proceso de evaluación y prueba en cada uno de los aspectos que esperamos como administradores de sistemas. Existen múltiples diferencias entre ambos proyectos, que tienen impacto real en el rendimiento y tiempo de configuración para lograr que el servicio quede funcionando perfectamente. Algunos prefieren NGINX por la sintaxis de configuración, otros eligen basado en las estadísticas presentadas y otros por simple experiencia con trabajos anteriores. Yo te recomiendo probar ambos y elegir según el proyecto, o quizás puedes usarlos ambos y sacar lo mejor de cada uno.
sudo apt search "nginx$"Verificamos si nginx esta en nuestro repo.sudo apt update && sudo apt install nginxActualizamos e Instalamos
- Si revisamos los logs por el comando anterior es muy probable que despues de haber instalado Apache diaga algo como
Not attempting to start NGINX, port 80 is already in use
- Si no supieramos que se esta ejecutando en el puero
80, con el comandosudo netstat -tulpnsabremos que puertos se estan utilisando. - Entonces primero apagamos Apache
sudo systemctl stop apache2luego iniciamos NGINXsudo systemctl start nginxy verificamos nuevamente el puertosudo netstat -tulpndonde ahora NGINX debe estar usando el puerto 80.
Archivos de configuracion de NGINX
- En Linux todos los archivos de configuracion se encuentran en la carpeta
etc, en este casols etc/nginxdonde tendremos los siguntes archivos:
conf.d koi-win nginx.conf sites-enabled
fastcgi.conf mime.types proxy_params snippets
fastcgi_params modules-available scgi_params uwsgi_params
koi-utf modules-enabled sites-available win-utfLos archivos mas usados son los siguientes:
a. nginx.conf Aqui podemos ver la cantidad de procesos que vamos a lanzar, cual es el Process ID, y el Usuario con el que se ejecuta nginx www-data.
b. sites-available/default Nos muestra toda la configuracion del servidor, aqui podemos activar PHP, el puerto.
c. curl -I localhost Head de la respuesta del Servidor.
d. sites-enabled Aquellos sitios activos en el momento.
NGINX Amplify es una herramienta SaaS que permite realizar el monitoreo de NGINX y NGINX Plus. Los factores que permite monitorear son:
- El rendimiento
- Configuraciones con análisis estático
- Parámetros del sistema operativo, así como PHP-FPM
- Bases de datos y otros componentes.
Nginx Amplify es de fácil configuración y llevar control de nuestros servidores es agradable por los tableros de administración que posee.
Con NGINX Amplify podrás recolectar más de 100 métricas de NGINX y el sistema operativo. Amplify analiza los archivos de configuración propios del servidor, detecta configuraciones incorrectas y da recomendaciones de seguridad, también permite crear notificaciones que pueden ser enviadas por correo o a un canal de Slack con un simple clic.
Los tableros de mando de Amplify sirven para verificar la disponibilidad del sitio e identificar situaciones anómalas en diferentes periodos de tiempo. Otra característica a destacar es que NGINX Amplify te permite administrar varios sitios, direcciones IP y un nombre para identificarlo.
sudo apt install pythonx.xInstalamos python- Movernos a la carpeta de Nginx
cd /etc/nginx - Modificar el archivo conf.d de la siguiente manera
sudo cat > conf.d/stub_status.conf
server{
listen 127.0.0.1:80;
server_name 127.0.0.1;
location /nginx_status {
stub_status on;
allow 127.0.0.1;
deny all;
}
}- Matar el proceso de Nginx
sudo kill -HUPcat /var/run/nginx.pid` - Reiniciar y habilitar Nginx
sudo systemctl restart nginx && systemctl enable nginx - Logearnos en el sitio web de Nginx Amplify y seguir las instrucciones de instalación: nginx, Iniciar el servicio de Nginx Amplify
service amplify-agent start.

- Se puede instalar en Ubuntu 20 de la siguiente manera: Después de darle los permisos de ejecución al archivo
install.shde abre convi o nanose edita la linea que dicepackages_url=se reemplaza la url de las comillas por estahttps://packages.amplify.nginx.com/py3/Se ejecuta como dice en Nginx AmplifyAPI_KEY=#### sh ./install.sh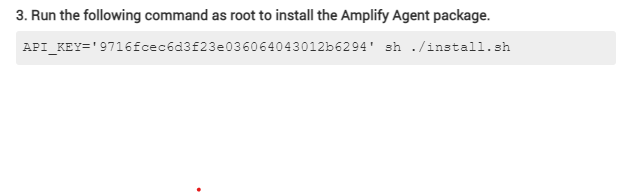
- Reiniciar Nginx
sudo systemctl restart nginx
- `sudo apt search "mysql-server$" buscamos si el paquete se encuentra en el repo de Ubuntu. Si la version que necesitamos no es encuentra en el repo entonces todo se debe hacer manual.
- Instalación de MySQL
sudo apt install mysql-server - Si perdemos acceso a mysql, entonces podemos ingresar a
cd /etc/mysqldonde encontraremos los siguientes archivos. Abrimos
Abrimos vim debian.cnfalli encontraremos la informacion del usuario.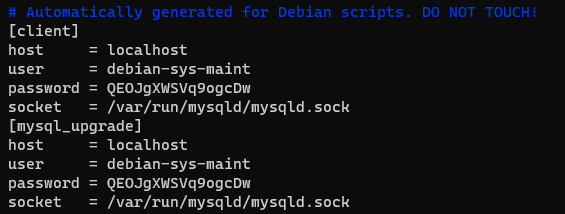
- Ahora si podemos conectarnos a la base de datos MySQL asi
mysql -u debian-sys-maint -p, enter y luego colcamos el passwordQEOJgXWSVq9ogcDw - Salimos de mysql
exitluego Asegurar el server de la base de datossudo mysql_secure_installationaqui nos aseguramos de usar un password fuerte, luego verificar que Apache esté funcionandosudo systemctl status apache2 - Activar módulos rewrite y cgi
sudo a2enmod rewrite cgi, asi nagios va a funcionar apropiadamente. Reiniciar Apachesudo systemctl restart apache2. - Crear un usuario para Nagios
sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminluego reiniciamos apachesudo systemctl restart apache2, he iniciamos nagiossudo systemctl start nagios - Entrar a Nagios en nuestro navegador web, escribiendo como dirección:
127.0.0.1:8080/nagiosluego de haber hecho log in con nagiosadmin, los servios aun deben aparecer detenidos solo si no hemos instalado los plugins de nagios de lo contrario deben estar en verde. - Nagios a diferencia de otros paquetes, tiene sus archivos de configuracion en
sudo /usr/local/nagios/bin/nagios -v /usr/loacl/nagios/etc/nagios.cfg
- Nos conectamos a mysql
sudo mysql - Crear un usuario
GRANT SELECT ON *.* TO 'nagios'@'localhost' IDENTIFIED BY 'nagiosplatziS14*';
-- (nagiosplatziS14*) es un Password no un usuario.
FLUSH PRIVILEGES; - Configurar Nagios
sudo vim /usr/local/nagios/etc/nagios.cfg
#Ya dentro del archivo, agregar la siguiente linea:
cfg_file=/usr/local/nagios/etc/objects/mysqlmonitoring.cfg- Crear comandos para hacer uso de Nagios
sudo vim /usr/local/nagios/etc/objects/commands.cfg
#Ya dentro del archivo, agregar las siguientes líneas:
define command {
command_name check_mysql_health
command_line $USER1$/check_mysql_health -H $ARG4$ --username $ARG1$ --password $ARG2$ --port $ARG5$ --mode $ARG3$
#ARG Se refiere a la posicion de los datos a ingresar como --username en la posicion 1 luego password en la posicion 2,etc.
}- Crear el archivo que nombrarmos en la configuración en el archivo
nagios.cfg
#El archivo debe estar vacio.v
sudo vim /usr/local/nagios/etc/objects/mysqlmonitoring.cfg
#Ya en el archivo, agregar las siguientes líneas
define service {
use local-service
host_name localhost
service_description MySQL connection-time
check_command check_mysql_health!nagios!nagiosplatziS14*!connection-time!127.0.0.1!3306!
}- Reiniciar nagios
sudo systemctl restart nagiossi algo no funciona entonces podemos apagar y encender nagios.
-
find /var/log/ -name "*.log" -type fBusca todos los.logen la ruta/var/log/ -
Comandos útiles
- find
/var/log/ -iname *.log -type f: Muestra los archivos de log que tenemos en el sistema sudo find /etc/ -mtime 10 2: Muestra los archivos de configuración que tuvieron salidas de error en los últimos diez minutosawk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr: Muestra las IP’s que se conectaron con nuestro servidor nginxawk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -nr: Muestra los errores que surgieron en nuestro servidor nginx.
-
Un servidor puede llegar a registrar millones de líneas de datos en un log. Para facilitar el monitoreo y mantenimiento podemos usar herramientas o tecnologías que nos permitan tomar esta información sin procesar y convertirla en visualizaciones fáciles de consumir y entender.
-
El primer paso para seleccionar las herramientas que usaremos. Lo primero es tener una base de conocimiento que nos identifique el servidor en circunstancias normales y de esta forma con la ayuda de estas herramientas detectar preocupaciones o incluso tendencias con una sola mirada.
Algunas herramientas que podemos tener en distribuciones Linux son:
-
Collectd Es un demonio que recopila datos de rendimiento, y junto con la herramienta collectd web, es capaz de generar reportes que se pueden visualizar en un navegador WEB. Se puede establecer un servidor y a él conectarle un número ilimitado de clientes remotos.
-
Nmon Obtener visualizaciones rápidas de mi sistema. Se instala con apt install nmon. Tiene una característica especial que me permite guardar en archivos de formato nmon que se pueden convertir en información que puede ser presentada en html con la herramienta nmonchart.
Nmon -f -s 15 -c 20, se recolectará información por cinco minutos mostrados en incrementos de 15 segundos 20 veces. -
Munin Es una herramienta para analizar el rendimiento del servidor que contiene gráficos históricos para facilitar la identificación de problemas en el tiempo.
-
Grafana Permite consultar, visualizar, alertar y ante todo entender las métricas de negocio sin importar dónde están almacenadas. Se puede crear, explorar y compartir tableros de mando con el equipo basados en el principio de la cultura orientada a los datos.
-
También podemos instalar agentes de monitoreo en los servidores, algunas opciones son newrelic y datadoghq/, podemos tener una prueba del servicio y analizar el rendimiento de nuestro servidor.
-
Cabe aclarar que también necesitará algún sistema de alarma automatizado que nos envíe alertas de forma proactiva cuando las cosas no estén funcionando bien.
Como administradores de bases de datos Linux debemos saber automatizar tareas, es por esta razon que utilizaremos pyscripts.
- ¿Qué es Bash? Es una shell de UNIX y el intérprete de comandos por defecto en la mayoría de distribuciónes GNU/Linux. Se pueden crear scripts, los cuales por convención terminan con la extensión
.sh - Creamos un script y debe tener la siguiente cabecera para el caso de bash
#!bin/bashluego si colocamos el codigo. Ejecutamos asi./script.sh. Aprender a programar en bash es muy necesario para el dia a dia de los administradores de servidores Linux.
env: Muestra las variables del sistema operativo$PATH: Guarda las rutas donde se ubican los archivos binarios que pueden ejecutarse directamente en la consola- Verificar la cantidad de espacio en el S.O.
#!/bin/bash
# Verificar la cantidad de espacio en el S.O
# Desarrollado por Jhon Edison
CWD=$(pwd)
FECHA=$(date +"%F%T")
echo $FECHA
df -h | grep /dev > uso_disco_"$FECHA".txt
df -h | grep /dev/sda2 >> uso_disco_"$FECHA".txt
echo "Se ha generado un archivo en la ubicación $CWD"En esta clase vamos a realizar un script que nos permita realizar una copia de seguridad de una base de datos MYSQL. Leer Crontab en Linux para automatizar otras tareas en la consola.
#!/bin/bash
# Description: Shell script to restore a backup from Mysql
#
# Desarrollado: Para platzi by Jhon Edison Castro @edisoncast
PATH=/usr/local/sbin:/usr/local/bin:/sbin:bin:/usr/sbin:/usr/bin
#La variable PATH describe las posibles rutas desde donde se podria ejecutar.
#Set -e Sirve para detener el script en caso de que el programa falle.
set -e
readonly SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
readonly SCRIPT_NAME="$(basename "$0")"
run
restore_backup
function assert_is_installed {
local readonly name="$1"
if [[ ! $(command -v ${name}) ]]; then
log_error "The binary '$name' is required by this script but is not installed or in the system's PATH."
exit 1
fi
}
function log_error {
local readonly message="$1"
log "ERROR" "$message"
}
function log {
local readonly level="$1"
local readonly message="$2"
local readonly timestamp=$(date +"%Y-%m-%d %H:%M:%S")
>&2 echo -e "${timestamp} [${level}] [$SCRIPT_NAME] ${message}"
}
function run {
assert_is_installed "mysql"
assert_is_installed "mysqldump"
assert_is_installed "gzip"
assert_is_installed "aws"
}
function restore_backup {
local BAK="$(echo $HOME/restore)"
local MYSQL="$(which mysql)"
local GZIP="$(which gzip)"
local NOW=$(date +"%d-%m-%Y")
local BUCKET="xxxxx"
local DATABASE="xxxxxxx"
USER="xxxxxx"
PASS="xxxxxx"
HOST="xxxxxxxx"
DATABASE="xxxxx"
[ ! -d "$BAK" ] && mkdir -p "$BAK"
FILE=$BAK/$DATABASE.$NOW-$(date +"%T").gz
local SECONDS=0
aws configure set s3.signature_version s3v4
aws s3 sync "s3://$BUCKET" $BAK --exact-timestamps
cd $BAK
local FILE="$(find . -iname "*.gz" -type f -print0 | xargs --no-run-if-empty -0 stat -c "%y %n" | sort -r | head -n 1 |awk '{print $4}')"
gunzip < $FILE | $MYSQL -u $USER -h $HOST -p$PASS $DATABASE
duration=$SECONDS
echo "$(($duration / 60)) minutes and $(($duration % 60)) seconds elapsed."
}Explicacion Víctor Macedo Becerril estudiante platzi
- El objetivo del script es hacer un backup de una base de datos, para ello primero se debe verificar que estén instalados ciertos paquetes en el sistema operativo es lo que se ve en esta clase. Antes de continuar es importante saber la definición de funciones en programación. Una vez sabiendo esto, empezamos el análisis del código:
-
El profesor empezó con el comando
-
set -esimplemente para detener la ejecución del script por si hay alguna falla. -
Después declaró dos variables de solo lectura. Estas son como variables globales, es decir, pueden llamarse aún estando dentro de funciones.
-
Después ejecuta dos funciones run y make_backup, estas dos funciones son declaradas más abajo en realidad en esta clase solo se ve la función run.
-
La función run ejecuta otra función
assert_is_insatalled, la cual recibe como parámetro los nombres de paquetes que la funciónassert_is_insatalledse va a encargar de preguntar si están instalados. -
La función
assert_is_insatalledinicia con la declaración de una variable name, la cual lee el primer argumento$1que recibe la funciónassert_is_insatalledque es el nombre del paquete a averiguar si está instalado. Para saber si está instalado el paquete solo hace un condicional cuya condición es si el comandocommand -v "paquete", da respuesta, si no da respuesta el comando, significa que no está instalado y ejecuta la funciónlog_errorcon argumentoThe binario …y después de eso marca un error con el comando:
exit 1
-
La función
log_errordefine otra variable que lee el argumento recibido y llama a otra funciónlogcon dos argumentos. -
La función
loglee los dos argumentos recibidos y crea otra variable con la fecha de ese momento, para después hacer una salidaechoespecificando que es un error>&2. Errores1 Errores2 -
En clonclusión se crearon las funciones
runyassert_is_installedpara saber si ciertos paquetes que se usarán están insatalados, y las funcioneslog_errorylogpara el manejo de errores.
Para ejecutar nuestra tarea de copia de seguridad debemos hacer uso de cron, el cual es un administrador regular de procesos en segundo plano que comprueba si existen tareas para ejecutar, teniendo en cuenta la hora del sistema.
Las configuraciones de las tareas a ejecutar se almacenan en el archivo crontab que puede ser editado con el comando crontab -e, si requerimos listar las tareas que tenemos configuradas ejecutamos crontab -l.
A continuación te muestro lo que se imprime en la pantalla al correr el comando crontab -e.
- Para establecer una tarea automatizada con cron se debe seguir un formato específico para definir una tarea como se muestra a continuación:
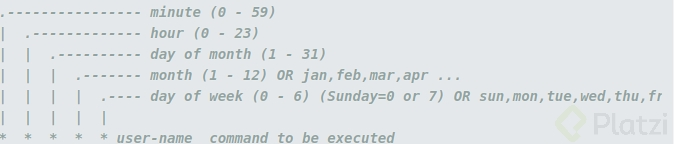
- Lo siguiente sería definir la periodicidad de nuestro cron, para ello podemos hacer pruebas en el sitio crontab. Nosotros queremos que nuestra copia se ejecute todos los días a las 03:15 de la mañana, pues es el momento donde menos tráfico tenemos en nuestra base de datos.
Entendiendo la gestión de vulnerabilidades CVE-2017-16995
Malas prácticas
- No desactivar el usuario root
- Realizar un login con usuario y password (sin ssh)
- No validar la versión de software usada
- Utilizar comandos r* o telnet
- No identificar los servicios y puertos abiertos en el S.O
- No gestionar correctamente los permisos de los usuarios.
Buenas prácticas
- Verificar las actualizaciones de seguridad y realizar la instalación de las mismas.
- CentOS
yum check-update --securityyyum update security - Ubuntu
apt updateyapt upgrade
Recuerda que la seguridad informática no es un producto, sino un proceso constante.
La Superficie de Ataque es el conjunto de vulnerabilidades o datos conocidos que pueden ser explotados por un atacante informático. Cada servicio de nuestras aplicaciones es un nuevo punto de entrada a nuestra red. No solo debemos proteger nuestros servidores, también debemos proteger todos los servicios que corren en él.
Lynis es una herramienta que analiza nuestros servidores y para darnos algunas recomendaciones. La estudiaremos más a fondo en una próxima clase. También existen frameworks o manuales como OWASP que nos explican las características de aplicaciones web vulnerables y cómo programarlas de forma segura.
El firewall y sus reglas
-
Los Firewalls son herramientas que monitorean el tráfico de nuestras redes para identificar amenazas e impedir que afecten nuestro sistema.
-
Recuerda que la seguridad informática es un proceso constante, así que ninguna herramienta incluyendo el
firewallpuede garantizarnos seguridad absoluta. -
En Ubuntu Server podemos usar ufw Uncomplicated Firewall para crear algunas reglas, verificar los puertos que tenemos abiertos y realizar una protección básica de nuestro sistema:
sudo ufw (enable, reset, status): activar, desactivar o ver el estado y reglas de nuestro firewall.sudo ufw allow numero-puerto: permitir el acceso por medio de un puerto específico. Recuerda que el puerto 22 es por donde trabajamos con SSH.sudo ufw status numbered: ver el número de nuestras reglas.sudo ufw delete numero-regla: borrar alguna de nuestras reglas.sudo ufw allow from numero-ip proto tcp to any port numero-puerto: restringir el acceso de un servicio por alguno de sus puertos a solo un número limitado de IPs específicas.sudo ufw app list: Para ver las apps permitidas
Recomendación
Abrir al público únicamente el puerto
80 http,443 https. Para un conjunto de IP’s específicas, habilitar el puerto22 ssh.
Escaneo de puertos con NMAP y NIKTO desde Kali Linux
Comandos
-
nmap -sV -sC -0 -oA nombre_de_archivo dirección_ip_del_servidor: Realiza un mapeo de la red -
nikto -h ip_del_host -o nombre_de_archivo: Escanea vulnerabilidades en un servidor. -
Uso de nmap:
-sVService/version info (Información acerca de los puertos abiertos).-sCPermite utilizar el motor de scripts.-OHabilita la detección de OS.-p-Escanea todos los puertos.-oAEnvía la salida a un archivo
Lynis: Herramientas de auditoria de seguridad en Linux
-
sudo lynis audit system: Realiza un escaneo del sistema operativo, mostrándonos sugerencias y el estado de peligro de ciertos detalles en nuestra distribución.
- Que es Node.js
git clone https://github.com/edisoncast/linux-platzi: Clonar el repositorio necesario para realizar la clase.sudo apt install nodejs npm: Instalar Node.js y npm.curl -sL https://deb.nodesource.com/setup_10.x -o node_setup.sh: Posicionados en el home, descargar Node 10.sudo bash node_setup.sh: Instalar Node 10sudo apt install gcc g++ make: Instalar gcc, g++ y makesudo apt install -y nodejs: Finalizar el proceso de instalación de la versión 10 de Node.sudo adduser nodejs: Agregar el usuario nodejs si todavía no lo creaste.node server.js: En la carpeta de linux-platzi, ejecutar el archivo server.js.- Crear un archivo de configuración para el servicio de Node.
sudo vim /lib/systemd/system/platzi@.service
# Una vez creado el archivo, llenarlo con la siguiente información
[Unit]
Description=Balanceo de carga para Platzi
Documentation=https://github.com/edisoncast/linux-platzi
After=network.target
[Service]
Enviroment=PORT=%i
Type=simple
User=nodejs
WorkingDirectory=/home/nodejs/linux-platzi
ExecStart=/usr/bin/node /home/nodejs/linux-platzi/server.js
Restart-on=failure
[Install]
WantedBy=multi-user.target- Ver lectura sobre Anatomía de un archivo de configuración de systemd.
- Cambiar el usuario a nodejs
sudo su - nodejs. - Clonar el repositorio necesario para la clase
git clone https://github.com/edisoncast/linux-platzi. -
Cambiar el nombre a la carpeta de linux-platzi a
server. Corregir los errores en el archivo de configuración del servicio en/lib/systemd/system/platzi@.service. Iniciar el servicio debemos estar en la carpeta/server/configuracion_servidor/bash../enable.sh./start.sh - Iniciar el servicio de Nginx Apagar antes Apache si es necesario
sudo systemctl start nginx. - Una vez en la carpeta
/etc/nginx/sites-available/eliminar el contenido de la configuración de Nginxsudo truncate -s0 default. 6.Editar el archivo de configuración.
sudo vim default
# Una vez en el archivo, escribir lo siguiente
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_http_version 1.1;
proxy_pass http://backend;
}
}
upstream backend {
server 127.0.0.1:3000;
server 127.0.0.1:3001;
server 127.0.0.1:3002;
server 127.0.0.1:3003;
}- Validamos que la configuración establecida fue correcta
sudo nginx -t - Reiniciamos nginx
sudo systemctl restart nginx - Probamos todo haciendo un
curla localhostcurl localhost. - Para que nginx pueda detectar los cambios, hay que publicar los cambios hechos en la carpeta
sites-enabled, y la forma de hacer es reescribiendo el enlace simbólico, para que esto se pueda hacer, se debe eliminar primero el enlace simbólico previo creado:sudo rm /etc/nginx/sites-enabled/default
Aprendimos a instalar paquetes desde diferentes distribuciones de Linux, utilizar comandos básicos, manejar usuarios y permisos, proteger nuestros servidores de diferentes vulnerabilidades, administrar procesos y servicios, escribir scripts en Bash para automatizar tareas, entre otras.
Te recomendamos continuar tu ruta de aprendizaje profesional con los siguientes cursos:
- Curso de Programación en Bash Shell
- Curso Profesional de DevOps
- Carrera de Administración de Servidores y DevOps
- Carrera de Amazon Web Services
- Carrera de Seguridad Informática
- ¿Cuál es la distribución más utilizada de Linux en servidores según w3techs?
Ubuntu Server - ¿Cuáles proveedores de nube me permiten lanzar instancias de Ubuntu server y CentOS como base?
Todas las mencionadas - ¿Cuánto tiempo de soporte tengo con las versiones LTS de Ubuntu?
5 años. - ¿Por qué debo elegir versiones LTS en Ubuntu?
Mayor tiempo de soporte en actualizaciones de seguridad y en software.5.¿Cuál es el mecanismo recomendado para validar la integridad de la imagen ISO descargada en la página de CentOS?sha256 - ¿Cuántos tipos de descargas puedo hacer desde la página de CentOS? ¿Cuáles son?
2: DVD y Minimal - Comando utilizado para concatenar y leer archivos:
cat - Comando para listar los archivos en formato largo, por orden de modificación y en orden reverso: ❌
ls -lSNada en el Video - Número de líneas por defecto que leemos con head y tail en un archivo:
10 - Modificador del comando tail que me permite hacer seguimiento del archivo en tiempo real:
-f - Como mínimo se requiere una partición para:❌
/homeMensionan algo de Swap. - Qué comando debo utilizar para usar comandos que requieren privilegios de root?
sudo - Archivo que contiene los usuarios del sistema:
/etc/passwd - ¿Qué comando debo ejecutar para usar el usuario nodejs?
su - nodejs - ¿Cuál es el grupo en CentOS que tiene permisos de administrador?
wheel - Comando que permite cambiar los permisos de un archivo:
chmod - Sistema numérico utilizado para cambiar permisos de forma numérica en Linux:
Octal - Si un archivo tiene el valor de permisos 400 quiere decir que:
Solo el usuario propietario puede leer el archivo. - Para poder ejecutar un script en bash, necesitamos el permiso de:
Ejecución para el usuario que lo quiere correr. - ¿Qué comando se puede utilizar para mostrar la información de la conexión de red actual (Dirección IP y MAC) en Ubuntu y CentOS sin instalar paquetes adicionales?
ip a - ¿Cuál es el protocolo que me permite conectar a otras máquinas Linux de forma segura y ejecutar comandos en un servidor remoto?
ssh - ¿Con qué comando puedo ver los paquetes instalados en una máquina Ubuntu?
dpkg -l - ¿Dónde se encuentra almacenada la base de datos de rpm?
var/lib/rpm/ - ¿Qué comando me permite ver los procesos corriendo en el servidor?
ps - ¿Qué comando me muestra la lista de procesos en background?
jobs - ¿Cuál es el comando que me permite editar el archivo crontab?
crontab -e - Al realizar la configuración de una base de datos, ¿cuál comando puedo utilizar para proporcionar seguridad básica en una base de datos MySQL o MariaDB?
mysql_secure_installation - ¿Cuál es el nombre del proceso que controla Apache y que se maneja con systemctl?
apache2 - Este parámetro en NGINX depende directamente de la cantidad de CPU que tengamos en nuestro servidor:
worker_processes - Después de almacenar información en una variable, ¿cuál símbolo debemos incluir para poder obtener su contenido?
./ - ¿Cuál operador redirige la salida de pantalla a un archivo y lo concatena al final?
>> - ¿Cuál es el Firewall instalado por defecto en distribuciones Ubuntu?
ufw - Comando para verificar los puertos en escucha de nuestro servidor:
netstat - Parámetro en nmap que hace uso de los scripts:
-sC - El reporte CVE-2017-18017 corresponde a:
Vulnerabilidad en el kernel de Linux antes de la versión 4.11, 4.9.x y antes de la versión 4.9.36